[筆記] Dataproc 收集 VM Node 監控指標
Table of Contents
前言 ¶
在預設情況下 Deataproc Cluster on Compute Engine 不會收集 VM Node 上的 Memory 與 Disk 監控指標。
以下我們常關心的 VM Node 監控指標需要透過 Legacy Monitoring Agent 或是安裝 Ops Agent 來收集:
- Disk usage: agent.googleapis.com/disk/bytes_used
- Memory usage: agent.googleapis.com/memory/bytes_used
在官方文件 Dataproc monitoring agent metric 提到:
Dataproc collects the following Dataproc monitoring agent metrics when you set –metric-sources=monitoring-agent-defaults. These metrics are published with the agent.googleapis.com prefix.
如果想要收集到這些 Agent 指標,在 Image 2.1 與 2.2 不同版本有不同作法。
Image 2.1 ¶
在 Image 2.1,Dataproc 預設安裝了 Legacy Monitoring Agent,但只有收集 Processes 相關的監控指標,Disk 與 Memory 則是沒有的。
我們必須要建立 Dataproc Cluster 時於參數設定 --metric-sources=monitoring-agent-defaults(官方文件)。
這個參數目前無法在 Cloud Console UI 上面設定,我們只能透過 gcloud CLI、RESTful API、Terraform 等方式設定,以下是使用 gcloud CLI 的範例:
CLUSTER_NAME=cluster-b857
REGION=us-central1
PROJECT_ID=<Your GCP Project ID>
gcloud dataproc clusters create ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--region ${REGION} \
--subnet default \
--image-version 2.1-debian11 \
--master-machine-type n2-standard-4 \
--master-boot-disk-type pd-balanced \
--master-boot-disk-size 500 \
--num-workers 2 \
--worker-machine-type n2-standard-4 \
--worker-boot-disk-type pd-balanced \
--worker-boot-disk-size 500 \
--enable-component-gateway \
--metric-sources "spark,hdfs,yarn,spark-history-server,hiveserver2,hivemetastore,monitoring-agent-defaults"
Image 2.2 ¶
在 Image 2.2,我們必須要安裝 Ops Agent 才能夠收集這些 Agent 指標。文件
在文件上沒有特別說明我們要如何安裝,但一般做法是使用 initialization action 來實現。
我們可以從文件中提到的 GitHub Repo initialization-actions 找到安裝 Ops Agent 的 Script。
文件中也提到對於該 GitHub Repo,Google 也有提供 Public Buckets,在最佳做法是,將該 Script 存放在自己擁有的 GCS Bucket 中使用:
REGION=COMPUTE_REGION
BUCKET=YOUR_OWN_BUCKET
gcloud storage cp gs://goog-dataproc-initialization-actions-${REGION}/opsagent/opsagent_nosyslog.sh \
gs://${BUCKET}/opsagent/opsagent_nosyslog.sh
我們使用 opsagent_nosyslog.sh 在 Dataproc Cluster 的 Node 上安裝 Ops Agent,並不收集 syslog 以節省費用。
這個參數可以在 Cloud Console UI 上面設定,或透過 gcloud CLI、RESTful API、Terraform 等方式設定。
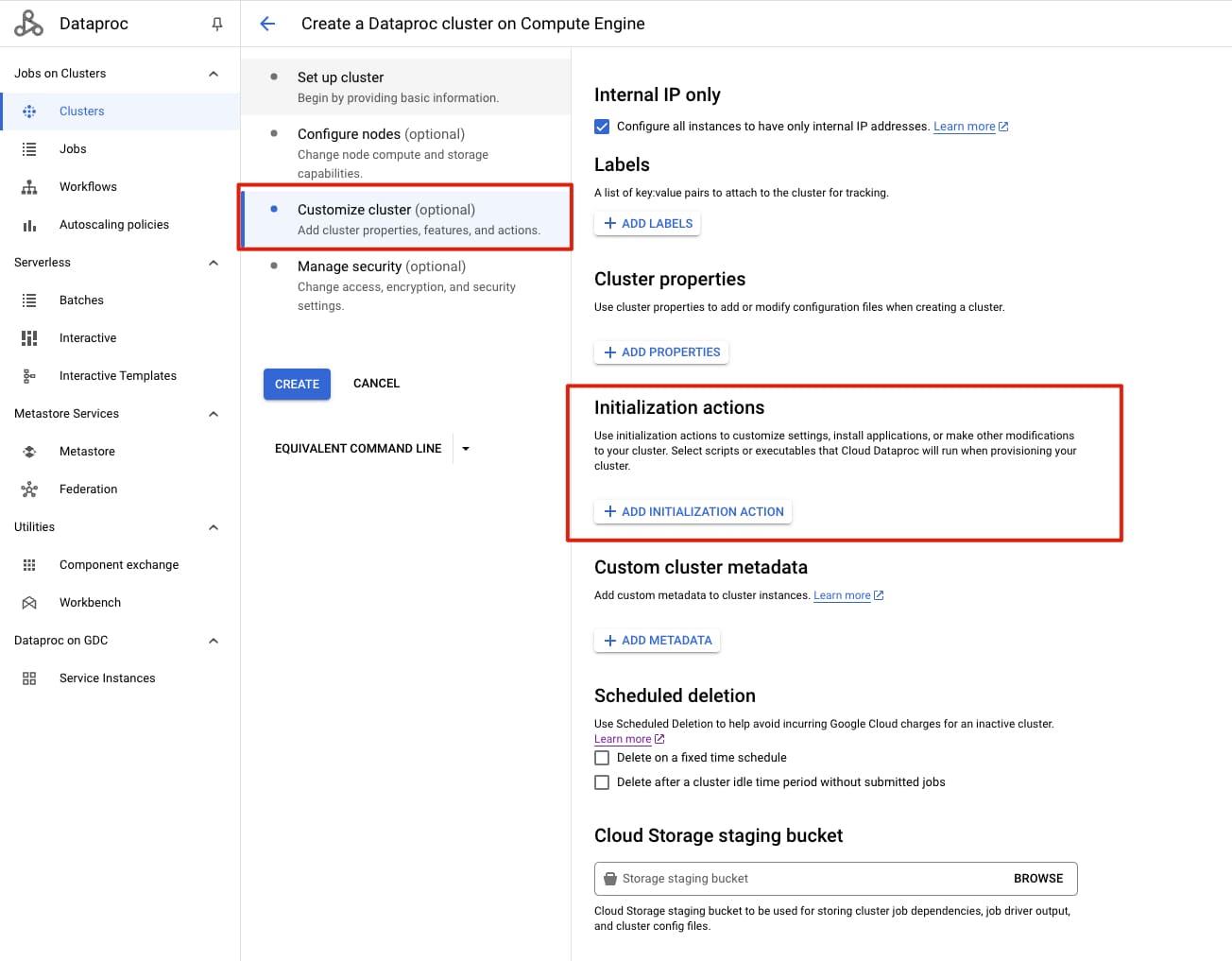
以下是使用 gcloud CLI 的範例:
BUCKET=<YOUR GCS BUCKET>
CLUSTER_NAME=cluster-b859
REGION=us-central1
PROJECT_ID=<Your GCP Project ID>
gcloud dataproc clusters create ${CLUSTER_NAME} \
--project ${PROJECT_ID} \
--region ${REGION} \
--subnet default \
--image-version 2.2-debian11 \
--master-machine-type n2-standard-4 \
--master-boot-disk-type pd-balanced \
--master-boot-disk-size 500 \
--num-workers 2 \
--worker-machine-type n2-standard-4 \
--worker-boot-disk-type pd-balanced \
--worker-boot-disk-size 500 \
--enable-component-gateway \
--initialization-actions=gs://${BUCKET}/opsagent/opsagent_nosyslog.sh
對於現存 Image 2.1 的 Dataproc cluster 的 Workaround ¶
以下方式為自行在 Node 上調整 Legacy monitoring agent(collected) 來收集 Memory 與 Disk 的監控指標,但這樣的作法無法套用在 Auto-Scaling 自動建立的 Node 上。
透過 SSH 遠端登入到 Dataproc Cluster 的 VM Node 上。
執行指令建立設定檔:
sudo vi /opt/stackdriver/collectd/etc/collectd.d/collectd_memory_and_disk_metrics.conf
檔案內容(這是從其他 Image 2.1 並啟用 monitoring-agent-defaults 的 Dataproc 擷取過來的設定):
LoadPlugin df
<Plugin "df">
FSType "devfs"
IgnoreSelected true
ReportByDevice true
ValuesPercentage true
</Plugin>
LoadPlugin disk
<Plugin "disk">
# No config - collectd fails parsing configuration if tag is empty.
</Plugin>
LoadPlugin memory
<Plugin "memory">
ValuesPercentage true
</Plugin>
PostCacheChain "PostCache"
<Chain "PostCache">
<Rule "df">
<Match "regex">
Plugin "^df$"
</Match>
<Target "write">
Plugin "write_gcm"
</Target>
</Rule>
<Rule "disk">
<Match "regex">
Plugin "^disk$"
</Match>
<Target "write">
Plugin "write_gcm"
</Target>
</Rule>
<Rule "memory">
<Match "regex">
Plugin "^memory$"
</Match>
<Target "write">
Plugin "write_gcm"
</Target>
</Rule>
</Chain>
執行指令重新載入設定:
sudo service stackdriver-agent restart
參考官方文件。